青云原创, GPU 虚拟化
转载请注明出处:https://navycloud.github.io/2017/08/05/gpu-preemption-in-virtualization/
本文将详细介绍AMD 显卡的GPU抢占功能以及在GPU虚拟化中的重要作用,理解GPU抢占需要适当的GPU原理基础,因此我也会适当笔墨部分基本的GPU Pipeline。
AMD GPU硬件虚拟化基本术语
由于本文并不是AMD GPU 硬件虚拟化基本原理教程,因此不会涉及基本原理方面的讲解,所以下面简单描述一下几个常见的术语。
- engine 指一种GPU 内部的计算资源,主要是指:GFX (graphics, 用于图像绘制),SDMA (用于数据搬运,复制),MM (多媒体,用于视频编解码)
- VF:指 Virtual Function, 也就是虚拟出来并pass through 给虚拟机的AMD pci device
- PF:指Physical Function, 也就是AMD GPU 硬件本尊的pci device
- world switch: 指对一个(或多个)engine进行调度切换,即将engines 从一个VF 调度给另一个VF使用, 这之中就涉及到抢占。
- Pipleline: 也就是GFX engine,即GPU渲染流水线,这是一个非常基本的GPU术语,各位可以google之,一大把资料,它就是游戏画面渲染的工厂,非常复杂,下面会简单描述。
什么是GFX pipeline
pipeline 是有多个模块组成的,多年来一直在不断地发展和变换,下面介绍一个典型的pipeline:
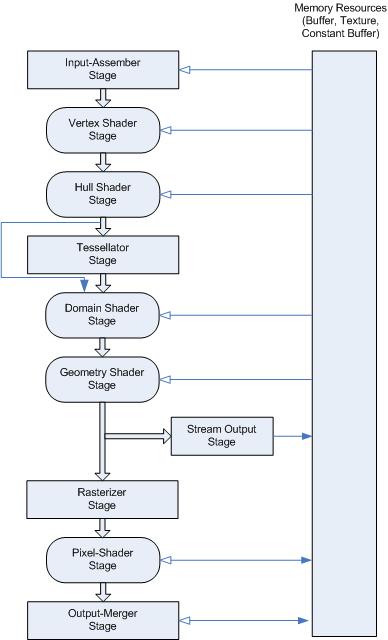
从这图(微软的DX11 pipeline)可以看到,pipeline发展到目前已经由很多环节组成了,但基本的模型并没有变:
首先需要游戏输入顶点数据(以及每个顶点附带的属性数据,例如法线,颜色,自定义数据等),然后vertex shader stage用游戏提供的”vertex shader” (shader是一种程序) 来处理每一个用户输入的顶点,是吞吐量非常高的SIMD计算方式。vertex shader具体做什么完全取决于游戏开发者怎么攥写shader程序本身,不过套路还是有的:例如把给定顶点从模型空间用矩阵转换为视角空间(具体参考计算机3d图形学),并结合此次具体渲染的对象做一些处理:比如渲染风中的树叶可以用一些随机数来小范围改变树叶上部分顶点位置,从而制造每一片树叶都在风中自然而又凌乱的婆娑效果,而不是步伐一致的抖动。(在可编程pipeline出现前,要达到这样的效果需要花费巨量的CPU运算)。
Hull shader stage 是为tesselator 这个feature服务的,它将VS的输出分组,例如每三个顶点形成一个三角形,称为一个patch,然后将这些patch根据给附带的属性(每一个patch都有属性数据,例如复杂度就是一个数据)将一个patch分割成更多的patch并输出,当然也可以完全不做任何修改直接输出,完全取决于游戏开发人员。
tesselator shader stage 是不可编程的,它的作用是根据之前的shader stage(Hull shader)产生的输出靠硬件“聪明”地自动衍生出更多的顶点,从而把模型变得更复杂(效果更好),AMD是第一个提出该概念的公司。
(在OpenGL 规范中,由于tesselator shader stage对开发人员透明,不可编程。因此直接把hull shader stage 和 tesselator shader stage 合并成了一个stage,叫做TESS control shader stage)。
domain shader stage 是让游戏开发人员用来将tesselator shader stage 输出的(大量的)顶点组成的patch(三角形,正方形,etc…) 的每一个顶点再转换为世界坐标系(tesselator shader stage 输出的patch的顶点坐标系是每一个patch各自的内部坐标系,因此这些顶点的x,y,z,w数值对世界坐标系无意义),亦包括这些顶点附带的属性值,例如它的法线向量,颜色,纹理坐标等。
Geometry shader stage: 作用不大,它是把一个一个三角形转换为三角形带(strip,比如相邻的两个三角形不需要用6个顶点表示,只需要4个),当然这也是取决于游戏开发人员的意愿,你可以什么都不做,也没毛病因为domain shader stage 得到的数据已经可以给光栅化引擎了。
Rasterizer stage (光栅化)就是把数学上的顶点坐标,以及附带的属性例如法线,颜色,纹理坐标,用户自定义参数等,根据屏幕分辨率用固定的算法把这些“数学”顶点映射到离散的屏幕上去,也就是像素。(数学上的顶点的位置坐标是浮点数,而屏幕的分辨率却是具体的整数,因此需要有个变换),它的输入是”数学“级别的三维空间的顶点坐标及其附带的各种数据,输出是二维平面的x,y坐标以及附带的数据(颜色,法线,深度值,模板值,等等)
Pixel shader stage就是通过Rasterize 的结果把每一个frag作为一个数据(离散坐标,颜色,法线,各种附带属性)传递给 pixel shader(也是游戏自己撰写的程序)处理,最终产生Pixel, Pixel就是像素,也就是屏幕上看到的每一个由颜色的点。
实际上,还有clip rectangle, color buffer, depth buffer, stencil buffer等“非可编程”的硬件模块会参与到最终图像的计算,但是这些都不需要详细描述,因为他们都不是可编程pipeline的核部分心,更无关乎GPU抢占。
以上就是微软DX11定义的pipeline,vulkan和OpenGL也有各自的定义,但是大同小异,AMD和NV的可编程管线硬件也都能完全100%支持这三个API定义的流水线,实现就是靠驱动软件,我们称之位3d驱动(DX11驱动,ogl驱动,vulkan驱动)。OK,GFX pipeline的介绍到此为止,下面是正题。
GPU 抢占
下面介绍重点,GPU的抢占流程。
什么是GPU 抢占
CPU 抢占应该不少读者已经了解,简单说也就是CPU在内核态运行过程中,它会找机会主动停止自己的运行(例如spin lock和软中断,tasklet的完成时间点,具体我没有一一核实),从而可以去服务另一个线程,目的是让响应速度变快,缺点是耽误了内核态的运行,而且一次CPU抢占也对应一次task切换,从而对整体的系统性能是有负面影响的。
GPU 抢占和CPU抢占类似,也是把GPU在运行中尽快停止,并服务另一个客户(客户在虚拟化的应用就是VF,在非虚拟化环境中可以是另一个执行体,例如另一个更高优先级的gpu command)。
GPU抢占泛指所有GPU engine的抢占,不过一般而言我们指的是GFX engine。
AMD GPU硬件虚拟化为何需要GPU 抢占
AMD GPU硬件虚拟化是基于分时复用策略的,意味着任意时刻对任意engine只能有一个VF在占用它,因此必须要通过world switch这种分时复用的方法来让每一个VF都有机会使用engine资源。每一次把一个engine从一个VF切出去,就是一次engine preemption(抢占)。
如果没有GPU 抢占,那么当world switch请求发到某一个engine上(例如GFX)时,该engine并不会去暂停工作,而是待当前工作完全结束才去响应world switch请求,这就造成一个问题:如果当前工作量非常庞大,那么会让其他VF 等很长的时间导致差用户体验,而且影响engine分配的公平性。
PS:即使有了GPU 抢占,也只是缓解问题,因为AMD 目前的GPU 抢占(对GFX 和MM engine而言)并不能立刻完成,它能多块得完成还是依赖于工作量的大小,只不过它比不抢占而彻底等待工作完成要快得多。对于SDMA engine而言抢占可以做到非常快,SDMA仅仅是数据传输的工作,所以可以做到立刻暂停。
题外话:当有多个VF同时运行游戏时,按照目前默认的分时复用策略,在实际游戏中会造成忽快忽慢的卡顿(GPU latency)现象,这个是有严格分时复用引起的,我在另一篇文章“AMD GPU虚拟化的按需调度策略”中提出了一个新的调度策略可以很大程度减少卡顿现象。
GFX engine 的抢占
GFX 抢占的原理并不简单,但是由于AMD内部的技术细节我不能public发表,因此就只能从概念上描述一下:
- 在GFX engine得到world switch请求时,这个请求指令是hypervisor通过programing其它硬件模块(RLCV,只需要知道名字就可以了,不必追究细节,我也不会透露)来通知CP 的,CP会负责GFX 抢占的所有工作。
- CP是command processor缩写,它是GFX pipeline的前端预处理模块(也是一个firmware),负责执行3d驱动填入command stream的指令,这些列指令有些负责设设置寄存器,有些负责同步信号量,有些负责读写内存,有些些是配置一些pipeline需要用到的资源等等。当CP处理到DRAW这个指令时就会给pipeline发送信号驱动pipeline开始工作,一旦CP收到rlcv的抢占请求时,CP就会在任意“可以抢占的指令”上发起抢占工作。抢占的主要工作内容就是保存当时的GPU GFX 上下文现场,具体如何保存,保存哪些,就不便展开了。抢占完成后,RLCV会通知SDMA去做抢占,全部完成后,RLCV会执行word switch,它也会保存另一部分寄存器,然后把GFX和SDMA切换到另一个VF上,也即是恢复另一个VF之前被抢占的工作。 整个world switch的流程可以简单描述为:
- RLCV发起抢占请求
- CP 收到请求,对gfx发起抢占,等成功后保存gfx的上下文资源,寄存器等
- SDMA收到请求,自我暂停并保存SDMA上下文
- RLCV待CP,SDMA都完成抢占后,根据一个SaveRestoreList对一些寄存器做保存处理(这些寄存器不会由CP和SDMA负责保存)
- RLCV会把需要恢复的VF的寄存器从该VF 的SaveRestoreList中恢复到VF中。
- RLCV会把CP,SDMA调度到该VF
- RLCV通知CP,SDMA去恢复之前被抢占的VF
- CP 通过一个叫DRAW的指令驱动GFX Pipeline工作,而pipeline一旦开始工作是不能停止的,必须等到pixel shader stage完成了才能停止,因此CP只能在每一次DRAW之后暂停GFX ENGINE,通常而言,3d驱动会在一次command stream中要求gfx engine做几百个或者上千上万个DRAW 操作,也就有那么多个时间点可以允许CP暂停使用pipeline,也就达到了所谓的抢占的效果,可以说目前AMD的抢占是比较粗粒度的。一次DRAW 的工作量有多大,就意味着抢占GFX需要等待多少时间才能完成,而DRAW的工作量取决于大致上两个指标:
- 一次DRAW指令会用到多少顶点,越多则shader engine工作也越多,这是3d驱动控制 的。
- 整个pipeline的各个shader写得有多复杂,极端情况如果某个shader是一个死循环,那就永远抢占不了,这种情况下GPU就死了,所有VF都不能工作了,必须要通过TDR得方法来拯救整个GPU。(关于TDR, 也即Time out Detection and Recovery,是我于2016年为北美云客户亚马逊在Linux AMD 虚拟化驱动上开发的一个feature,此前AMD 的Linux内核驱动乃至整个linux 中的所有各厂商upstreaming的显卡驱动都没有TDR 这个功能,我会抽空另写一篇描述TDR)。
NOTE:
- DRAW一旦开始不能被抢占,只能等他完成,因此一个含有1000个DRAW的command stream中理论上有1000个点可以被抢占。
- 在DRAW之前,command stream中会有设置各类shader程序的指令,用以告诉GFX ENGINE当pipeline开始工作时,各类shader指令在哪段内存中。
SDMA engine 的抢占
这就比较简单了,概念上仍旧是收到RLCV的抢占消息后最快速度的保存,下次再恢复,但是SDMA由于硬件实现简单因此可以做到立刻抢占。
multi-media engine 的抢占
这块比较复杂,但是远远没有GFX复杂,基本上也是粗粒度的暂停,保存,恢复操作。区别是mm的抢占发起方不是RLCV,而是一个叫MM-SCHEDULER的模块,不过本质上没有区别啦。
本文到此结束,Farewell!