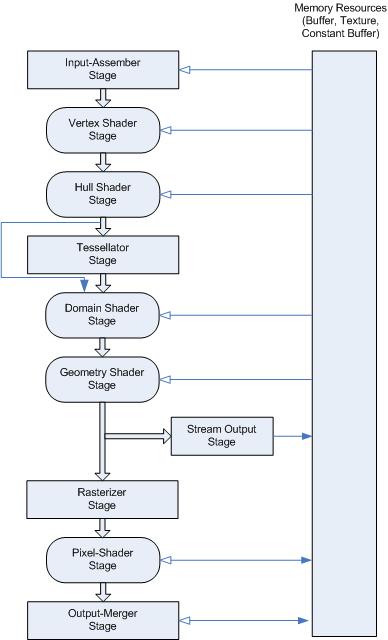
青云原创, GPU 虚拟化
转载请注明出处:https://navycloud.github.io/2018/07/27/on-demand-scheduling/
本文主要内容是给大家分享一下笔者最近在工作中关于GPU虚拟化调度策略的一点小小的研究成果,因此并不会详细地讲解AMD GPU虚拟化技术原理与实现,仅从概念上带过,目的是让观众关注调度策略本身。关于AMD GPU虚拟化基本原理与实现我会抽空另写一篇。
note: 本文面向对GPU硬件和驱动有一定基础的同学,当然没有基础也可以嗑瓜子看看
AMD GPU虚拟化方案简介
首先简单介绍一下AMD 的GPU 虚拟化方案。
AMD给客户的虚拟化方案整体上是一套基于SR-IOV的硬件虚拟化方案(关于SR-IOV读者可以自己google之),所谓基于硬件的虚拟化就是尽量用硬件和firmware去实现GPU的基本功能,且尽量维持物理机GPU驱动软件的复用程度。Intel的方案是基于软件的GPU虚拟化,他们的方案中guest KMD(guest kernel mode driver) 和bare-metal(物理机系统称为bare-metal)相比有较大的改动,主要是command submit和memory manage部分,比如intel的command submit在guest KMD中实际上并不会把command 提交到hardware上,而是通过hyper call的方式提交给HMD (hypervisor module driver),当然hyper-call只是一种说法,实际的做法可以通过修改QEMU来实现而不一定必须是hyper-call,例如修改QEMU代码,创建一种新的虚拟GPU 设备,并且为这个设备的MMIO(寄存器)做trap。当虚拟机 access这些MMIO 时QEMU就会拦截并调用vendor实现的callback函数,从而实现hyper-call的作用,例如guest需要吧一段虚拟机内存映射到GPU 地址空间时就会去设置一些MMIO寄存器, 而这些MMIO寄存器都是QEMU 虚拟出来的并且可以截获,从而让HMD就有机会把这段guest physical address 转成 host physical address 后再映射到GPU 地址空间,把 GPA 专为 HPA的原因是:GPU只能访问真正的物理内存地址,虚拟机中的guest physical address对于GPU而言是无意义的。
注:以上对intel GPU虚拟化方案的技术描述完全是我个人不责任地主观臆断,且没有任何事实依据,本人暂时也没时间去研究 Intel的虚拟化开源代码,intel的同仁如果觉得我胡说八道请轻微diss一下即可。
反观AMD的方案,由于利用SR-IOV 这个标准,由此在host端可以看到多个(目前最大16个)virtual function device, 也就是虚拟出来的PCIe 显卡(简称VF),然后把这些VF pass through 给QEMU虚拟机,因此从软件上讲QEMU完全不知道这些VF 是虚拟出来的。那么VF 能不能完全像物理GPU 一样进行绘图渲染呢?
你猜到了,并不能!AMD的VF 其实并不是完全的硬件虚拟化设备,它其实有只有若干block是硬件级虚拟化的(硬件级虚拟化就是说每一个VF 都有各自独立的ASIC电路为这些block服务),以下这些block被真正硬件虚拟化了:
- IH (硬件中断服务, 每个VF 都自己独立的MSI/MSIX 硬件服务)
- GMC (GPU memory controller),每一个VF 都有自己独立的MC 模块,从而每一个VF 都有自己的GPU地址空间,完全独立运作
- IOMMU (这个是主板芯片组上的硬件,不是AMD GPU中,我把它列在这里是因为IOMMU 的作用本质上是GMC模块在虚拟化方案中的延申和继承,后面详细描述)
好了,接下来就是非硬件虚拟化的block了,说来也无奈,这个非硬件虚拟化的block才是GPU中最复杂,最庞大的模块:Graphic Pipeline,没错!就是这个GFX Pipeline 负责渲染你吃鸡时看到的所有的花草树木,建筑,敌人。。。AMD的人简称它为pipeline或GFX(计算机3D图形学就有pipeline这个软件概念,对应到GFX engine上就有硬件pipeline了,硬件pipeline实现了软件pipeline定义的功能)。
AMD的GPU虚拟化方法和CPU的进程切换是类似的,即分时复用:AMD的HMD(称为GIM)会给每一个VF 一定的时间片(例如6毫秒),时间片内GFX属于它,到点后就把GFX调度到另一个VF,如此每个VF 并不知道它此时是否占有GFX,也不需要知道。每一个VF只需要提交command到GFX ring上就可以了(GFX ring的作用就是让OpenGL/D3D 等User Mode Driver 提交cmd的一段环形buffer,CPU写,GPU读取并执行),当时间片切到它时cmd会被处理,当时间片用完后没有完成的cmd会被抢占(称之为MCBP,Middle of Command Buffer Preemption, 我会抽空写一篇文章简单描述AMD的MCBP实现),抢占后GFX 会被调度到另一个VF,当下一次之前被抢占的VF 得到GFX 时,它之前被抢占的那个cmd会继续执行 (resume execute)。
AMD的GPU和Intel的一样,都需要访问真正的物理内存地址,因此必须要把GPA 转为 HPA。由于QEMU知道有VF pass through 给了虚拟机,因此在虚拟机开机前QEMU 就为每一个VF建立了一张地址转换表格,该表格实现GPA 2 HPA,因此一旦有command提交到VF的GFX ring (GFX ring所占用的地址同样被IOMMU 转换后再让GPU 读取)后 GFX 正常执行,当GFX/GPU需要读取内存时,GPU会把地址送给GMC,GMC会把地址送出到PCIE总线上的IOMMU,IOMMU会按表格先把GMC给的GPA 转为HPA,并读取内容,最后把内容返回给GMC(如果是GPU 写入内存也是类似的套路)。因此整个过程除了两个硬件模块(GMC,IOMMU)没有其他软件或者硬件模块知道这件事儿,GPA 2 HPA对其他模块来说就是透明的。
当然GPU也不是访问任何地址都需要IOMMU, 当GPU 访问自己的显存(local Video Memory)时完全在GMC内部decode地址,所以性能非常好,不走IOMMU 的translate。
综上所述AMD的虚拟化方案不需要修改大量的KMD代码,只要改大约10%的代码就能把普通的KMD 运用到虚拟机里面,原理简述到此为止,现在步入正题。
AMD GPU 虚拟化现有调度方案及其缺点
在本文发表前AMD使用的GPU 调度方案称为round-robin模式,顾名思义就是一个一个轮流来,每个VF 一段时间片,未来一段时间内AMD会给某些客户试用笔者开发的新模式,我称之为on-demand模式,当然名字可能会被高层改得更优雅诗意一点,毕竟我只是个搬砖的粗人。
round-robin 模式简单说就是给每一个VF 一段固定的时间片,用完就对该VF做抢占(抢占就是让GPU停下来,类似于CPU的进程切换,都需要一些时间开销),抢占后再调度到下一个VF,我们这里举例说明这个方法的缺点,请看下图(下图假设每个VF 分配4毫秒时间片):
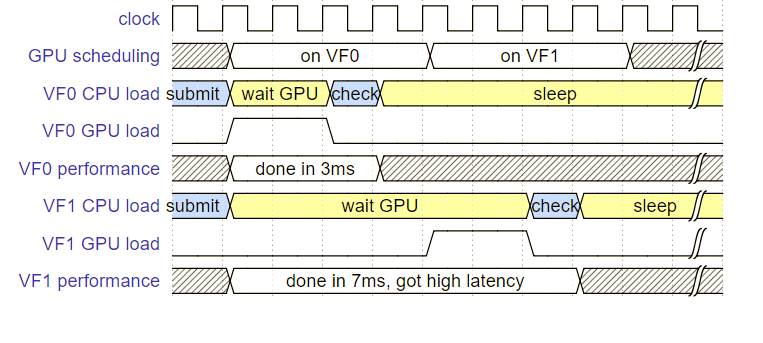
请仔细看这张图,它清晰准确地反映了round-robin模式最大的缺点:
该图给定两个VF分别对应两个虚拟机,每个虚拟机的CPU 都在同一时刻对各自的VF提交了一个cmd,假设VF0恰巧先得到了时间片(如图),由于该cmd只需要2毫秒就能完成,于是VF0没有任何延迟地就完成了工作,共花3毫秒完成了这一桢(假设GPU花费2毫秒,CPU收到中断通知,检查结果,汇报给UMD花费1毫秒)。由此可以算出对VF0而言这一桢的fps是1000/3 即 333桢每秒。
VF1也在跑同样的游戏,但这一帧却得到了差很多的结果:VF1的CPU提交cmd后,由于GPU不在VF1上,因此过了4毫秒它才得到GPU资源,然后同样花2毫秒完成这一桢,CPU再花1毫秒善后,最终这一桢共花了7毫秒,可以算得fps为 1000/7 即 140桢每秒, 只有VF0的一半都不到。
以2VF 为例,下面举例两种典型的悲剧case:
- 此时VF0占有GPU资源的这5ms内有cmd扔给VF0处理,因此VF0短时间内FPS达到最高,然后VF1忍受这低延迟,低fps。如果我们粗糙地用平均fps去统计目前的性能,也许我们会一位VF0+VF1的平均fps并不低嘛,但仔细一看,VF0的fps是200桢,而VF1只有50,因此VF1的玩家是不满意的,而VF0的玩家也没有得到非常大的满足,毕竟超过60的FPS已经意义不大了。
- 此时VF0占有GPU 资源的这5ms内并没有cmd扔给VF0处理,例如此时VM0的CPU在做一些非图形相关的计算等,或者游戏开了VSYNC所以还没有cmd扔给VF0处理,那么这个就更杯具了,因为这5ms内VF0和VF1都没有得到GPU 服务。
另外,由于AMD显卡的按时调度是基于MCBP抢占的,而MCBP抢占往往不是立刻成功的,因为MCBP只能发生在gfx 的pipeline完成后,因此5ms时间片内如果VF0一直在忙的话,MCBP命令下达之后往往还需要过几ms甚至几白ms才能调度到另一个VF上,这也是另一个latency问题的主要原因。
BTW:AMD把GPU调度工作称为“world switch”,每一个虚拟机是一个world,把GPU从VF0调度到VF1 就是一次world switch作业。
为什么需要这套”on-demand“调度策略
显然round-robin的方法只有在一种情况下不会白白浪费GPU资源,那就是任何一个VF 都在永远不停地提交cmd给GPU,但这显然是少数情况,对于多数云游戏客户而言,虚拟机只会跑一个GPU 负载不太大的游戏,因此这种情况下GPU 大部分时间都是闲置的,而且还会出现每个VF都时不时掉帧,卡顿的现象,就像上图中的VF1,这个现象我们称之为”latency“。所以需要一套新的调度策略尽量避免round-robin策略的浪费GPU资源的问题。
为了解决这个问题,新的按需调度策略需要从如何不浪费GPU资源的角度入手:当VF得到GPU后如果占着茅坑不拉屎没有cmd执行,需要立即主动让出GPU 资源(yield 机制)。
新的”on-demand“调度策略
按需调度策略的要点是三点:
- 【yield 机制】虚拟机需要在确认自己不用GPU资源时竟快通知hypervisor,并且hypervisor需要竟快做world switch
- 【电梯算法】每次做world switch前,hypervisor需要先check一下这个VF是不是有pending cmd(必须实现非常快速check否则就是浪费GPU时间),如果没有的话压根就不用调度给他GPU 资源,直接下一个即可。
- 【锁死桢速度】虚拟机运行的游戏最好给他定一个vsync,例如60hz或30hz,如此一来当一贞画完时,该虚拟机不会立刻submit下一帧的cmd,而是会有一定时间的等待,这就可以激发要点1。
第一点和第二点是最核心的,第三点根据客户实际情况可以调整。下面说说怎么做到第一和第二点。第一点我给它起了一个名字来描述这个feature – ”VF yield“,顾名思义VF 可以yield自己从而提前让出GPU资源
1. YIELD 机制
该feature需要两个软件模块同时配合,1)guest的KMD; 2)hypervisor端的HMD – GIM (GIM是 在hypervisor端的一个HMD模块,主要职责就是执行world switch)。 guest KMD 需要有一个方法可以立即判断出自己当前时刻是否不需要GPU资源,如果不需要就立刻通知GIM,GIM收到通知后立刻做world switch。
guest KMD 如何判断此时此刻是否需要GPU资源? 这个方法是一个trick,但是目前我只在Linux系统上实现了,windows guest需要用其它方法变通实现,我暂时只关注Linux,下面讲在Linux guest上的实现:
在gpu scheduler中 (gpu scheduler 是指guest kmd中的模块,并不是GIM中的做world switch的调度器,不熟悉AMD软件的童鞋比较容易困惑,这个模块的功能是公平地把每个进程的cmd公平的交错提交给GFX ring),每一个cmd提交到ring buffer后,都会在gpu scheduler维护的一个双向链表中插入一个job来代表该cmd,当一个jcmd完成后,中断会通知CPU,CPU 会把相应的job从该双向链表中删除,整个过程都是有同步锁保护,这个链表可以完美地反映对这个VF 而言哪些job/cmd正在运行,哪些刚刚完成,哪些还没开始。
note: 该双向链表叫 “ring_mirror_list”
下面讲这个trick,当一个job提交时,如果判断mirror list是空的,就说明当前ring突然从idle状态切换到了busy状态,我把这种case称作“idle2busy”,如果job提交时mirror list 不是空的,说明这个job提交的时刻该VF 上已经有cmd正在让GPU 处理中(是逻辑上正在让GPU 处理中,因为GPU 此时可能调度在另一个VF 上),因此这个job的提交就不会触发 “idle2busy”。ok理解了这点再继续理解与之相反的一个概念— “busy2idle”: 当一个job完成时中断会通知CPU,于是CPU会把这个job从mirror list中remove掉,然后再去check mirror list,看是否mirror list已经empty了,如果empty那就说明这个刚刚finish的job是这个VF 最后一个需要处理的job,且这一时刻没有其他cmd 悬挂在GFX ring 上,因此是一个“busy2idle” 的状态切换。
有了以上tricks,guest KMD 可以对每一条ring (AMD的GPU比较复杂,除了GFX ring外还有很多其他ring,例如DMA ring, compute ring, multimedia ring)瞬间检查出是否不再需要该ring所对应的GPU 资源(有cmd完成时可以检测出是否为idle2busy),或者该 ring是否有一个job初次提交从而可以知会GIM自己需要被调度,不要被电梯算法直接skip掉(有cmd提交到ring时可以检测出是否有busy2idle)。如果不在guest KMD的gpu scheduler里面做手脚,而是用measuring的方法去测量GPU是否idle,那会非常低效率,因为测量这个过程本身就需要时间去取采样点,而测量所消耗的时间就是对GPU资源的白白的浪费。
note: ring buffer的概念非常普遍,Intel,AMD,Nvidia 都有,这里就不赘述了,不懂的同学自己baidu/google吧,简单说就是一个环形buffer,GPU 读取cmd并执行,CPU 写入cmd。
由于AMD的GIM是一次world switch同时作用于 GFX/COMPUTE/DMA 这些GPU资源的,所以我们不能仅仅针对GFX ring 采用这个trick去监测,要对所有的ring都check,具体实现是:
- 当任意一条ring有cmd提交时,如果判断这个job是触发了”idle2busy”, 则:set_bit(ring->index,&rings_status),用以表示该ring是busy状态。(每条ring都有一个索引 index)
- 当任意一条ring有cmd完成时,如果判断ring buffer已经空了,就认为该job触发了“busy2idle”, 则 :clear_bit(ring->index, &rings_status),用以表示该ring是idle状态了
- 当任意一条ring触发了”busy2idle“事件,立马check 是否rings_status为0,若为0则说明此时此刻所有的ring都idle,于是立刻通知GIM 这个VF需要”yield“(AMD用中断方式让guest发消息给GIM),GIM收到YIELD通知后立刻做 world switch,从而赚取了这个VF 本来白白浪费了的时间片。当然如果不幸在world switch后该VF 又立刻有cmd提交那也是天命如此,不必钻牛角尖,这个世界上没有完美的调度方案。
2. 电梯算法
电梯算法这个名字是我老板起的,他在两年前首次创新性地提出了这个想法并实现了它,不过当时他是在GIM中用读取寄存器的方法来判断的(可以读取某些寄存器判断给定的VF 是否有pending job,没有的话跳过它下一个)。由于一些硬件的policy原因,电梯算法不能在MI25上用了,有部分VF寄存器不再允许访问,因此我实现了一个纯软件的实现:同样是利用”idle2busy”事件,方法是:
- 若任意一条ring触发“idle2busy”, 则:set_bit(ring->index,&rings_status),用以表示该ring是busy状态。(此条规则上面YIELD机制提过) ,并且检查是否 (ring_status & ring_status-1) == 0, 如果为 0 就发中断通知GIM标记此VF为BUSY,如此该VF 下次被GIM轮询到时就不会被skip掉。(ring_status & ring_status-1) == 0 说明ring_status只有一个bit是1,也就是意味着此次触发“idle2busy”事件的ring是整个GPU资源上第一个触发“idle2busy”的,因此这个时机通知GIM是合理的,我们并不需要每一条ring在触发”idle2busy”后都通知GIM,因为中断次数经量要少。
- 当任意一条ring触发了”busy2idle“事件,立马check 是否rings_status为0,若为0则说明此时此刻所有的ring都idle,于是中断通知GIM需要对该VF 标记为IDLE,如此下次轮询到该VF时可以skip掉它。
- 在GIM端:每次GIM做world switch时可以先检查该VF是否为BUSY,若为BUSY就正常调度它,否则就跳过。
3. 效果如何?看图说话
下面请看使用了“on-demand”策略后的图:
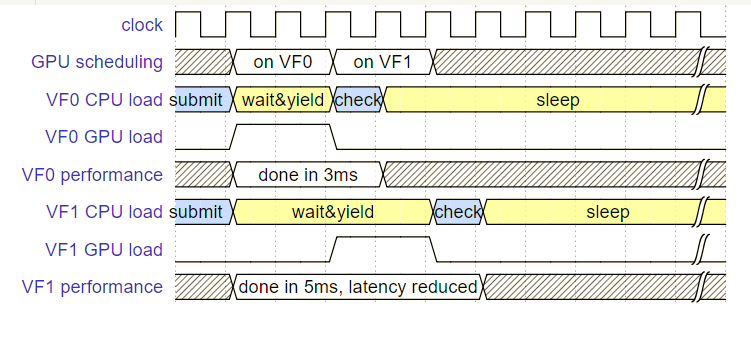
下图为原始的round-robin策略,贴出来方便对比:
为了实现整个思路,GIM里面的world switch调度实现改写了很多,因为需要做到实时性(即是一旦VF 要求yield,GIM要立刻做world switch,否则就会浪费GPU宝贵时间片),而原始的GIM在实时方面做得不够好,笔者的实现基本做到了50us以内响应guest发起的yield信号并开始执行world switch,原本的GIM需要300 ~ 500 us。
目前在MI25(vega10)上实现了这个新的调度策略,过段时间有空的话我会把该策略移植到S7150(tonga)上,毕竟S7150有不少国内客户正在使用,确认合法后我会把s7150的方案源代码上传到我自己的github(GIM + guest KMD)。
实现这套调度算法,我并不是希望单纯得提高所有VF的平均VPS (但这确实达到了这个个次要目的),我的目的是减少latency的频率,从而提高每一个VF的用户体验。现在总结一下为什么新的算法可以提高每一个VF的相应速度:
- 由于一旦VF发现自己不需要GPU,在时间片内它仍旧可以立即yield从而让出GPU资源,因此GPU的利用率得到了提高(结合开启vsync后,每个VF 都会有更多的机会检测出自己可以yield出GPU资源,因此效果更好),同时其他VF的cmd被更快得执行了(相对与round-robin)
- 由于GIM在调度GPU给一个VF前会用电梯算法检查它是否有work load,没有的话直接跳过该VF,因此GPU的利用率得到了提高,同时其他VF的cmd被更快得执行了(相对与round-robin)
- 由于MCBP本身是往往会引起一定时间的开销,而主动让出GPU资源就很好的规避了MCBP的发生(主动让出是因为检测出暂时不需要GPU资源,因此一定不是cmd执行了一半没有结束的状态,因此此时GIM对该VF下达MCBP命令后可以瞬间完成),避免了MCBP的发生就是节省了GPU的时间,因此同时其他VF的cmd被更快得执行了(相对与round-robin)
注:AMD官方的S7150的guest代码已经upstream了,下载最新的kernel就有,S7150的GIM代码没有upstream,但是open source了,在GIT上有,我不记得具体地址了。。。
4. 为什么windows guest需要用其他方法变通实现YIELD
对于windows guest,由于它的gpu scheduler是微软自己实现的,因此逻辑都在windows 内核中,于是windows KMD 没有办法抓到ring的status,不像Linux的gpu scheduler,是我们内核驱动开发人员自己实现的所以可以随意improve。后续有可能还是要研究windows上该如何做,有个变通方法暂时不表,因为该方法只有了解AMD 硬件的人才看得懂,因此没有太大意义在此处描述。
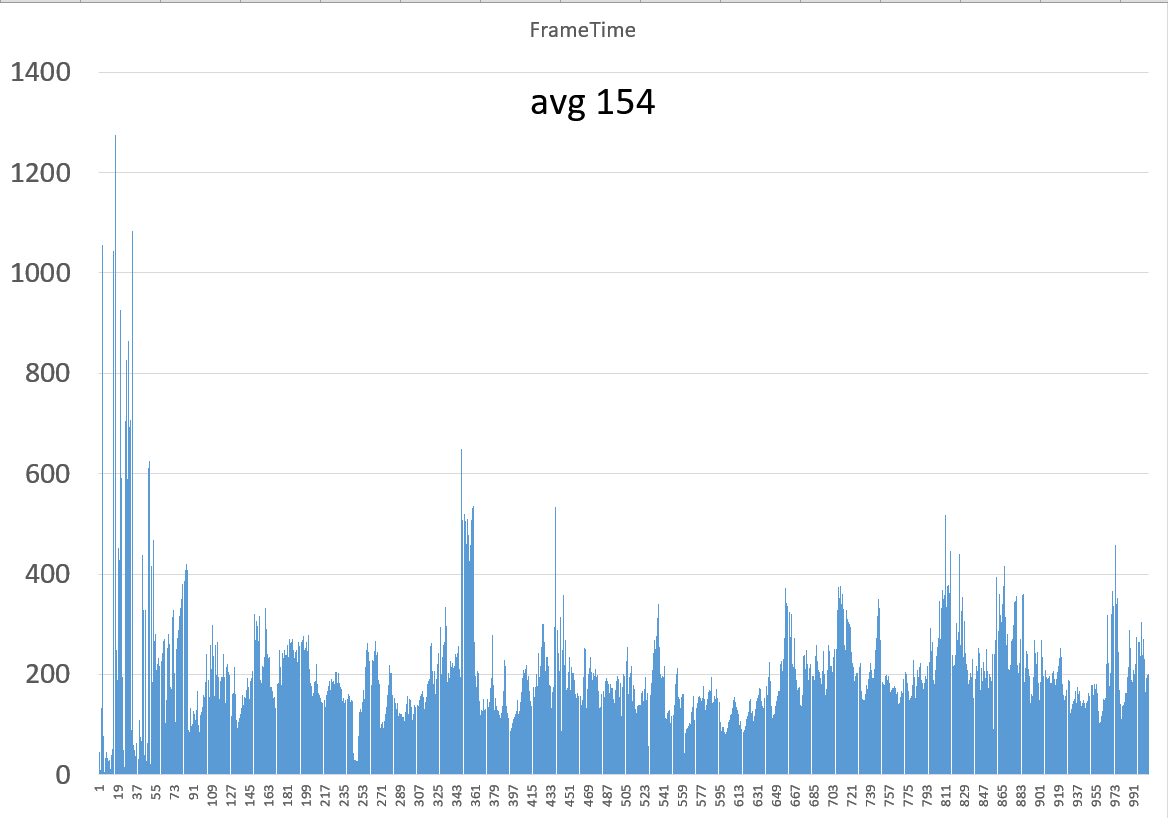
具体游戏测试FPS图
我用Nexuiz 这个OGL游戏做了一个对比测试,首先物理机跑下来是154 fps,然后我分别用round-robin和按需调度在4 VF下做了测试,结果如下:
round-robin下,4个VF 的avg fps分别为:76,79,73,78, total一起是306。
按需调度下,4个VF的avg fps分别为:94,95,120,98,total一起是407。
可以看到首先avg fps就提高了25%。
然后再放上三张图,分别是物理机,RR调度,以及按需调度下的FPS曲线图(RR调度取了FPS 79的那个VF 的图,按需调度去了FPS120的那个VF 的图)
物理机:
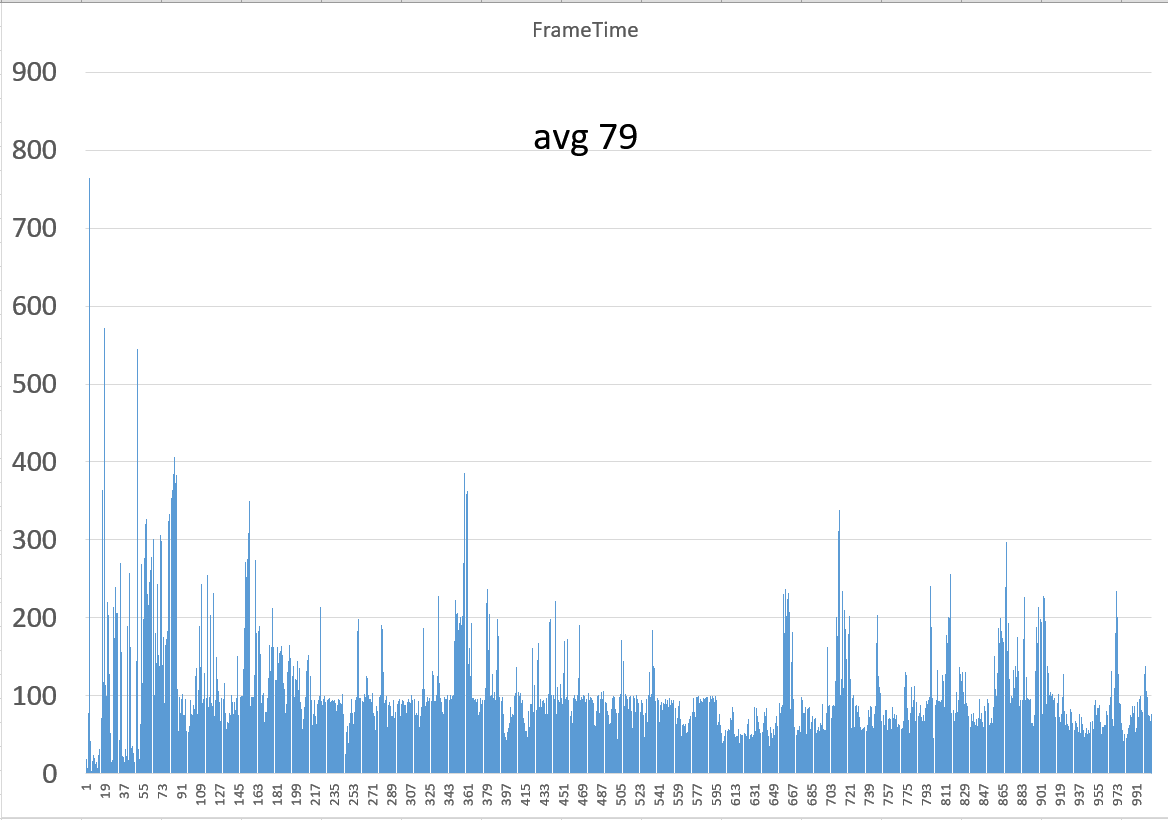
Round-Robin 下的某VF:
按需调度下的某VF:
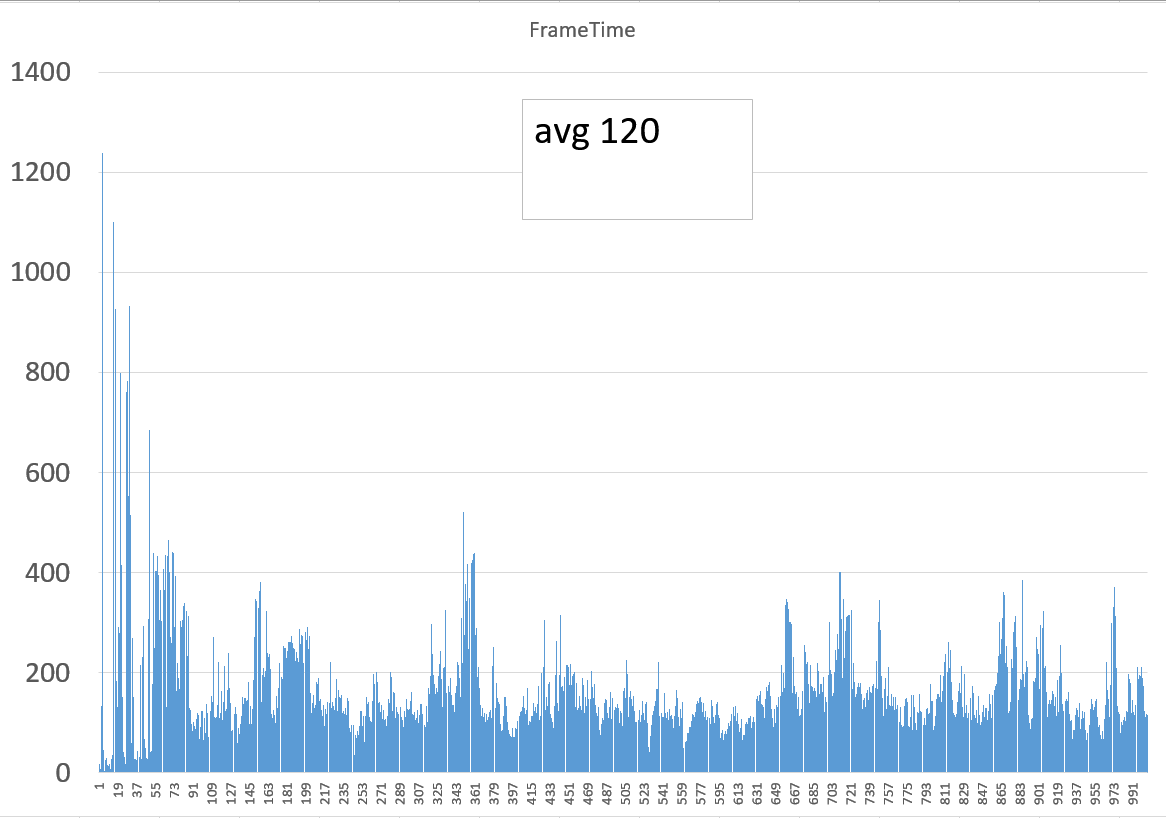
大家可以看到,按需调度的FPS曲线图,从曲线上看更接近物理机模式的图(这就是由于延迟被降低的缘故),就好像是物理机的fps曲线图在振幅上打了个折扣一样;而RR调度的图像方波图,即一高一低跳跃明显(当占有GPU时FPS会非常高,当其他VF占有时自己的桢会遭受延迟处理,因此FPS会下掉),因此,而且形状上也不太贴近物理机的曲线图。
理论上,每一帧的导数与物理机的每一帧的导数越接近说明延迟越少,以后我会考虑写脚本去做定量的数值分析来判断调度算法的质量,而不是目前这种靠肉眼观察fps曲线图的主观判断,定量分析算法如下:
prepare data
fps_bm = bare-metal.frames.avg;
for each “idx” in all frames -1
bare-metal.frames[idx].delta = bare-metal.frames[idx+1].fps - bare-metal.frames[idx].fps;
for each “X” in all VFs:
fps_VF[X] = VF[X].frames.avg;
scaling[X] = fps_bm/fps_VF[X];
for each “idx” in all frames -1
VF[X].frames[idx].delta = VF[X].frames[idx+1].fps - VF[X].frames[idx].fps;
Do the calculation for the score
for each “X” in all VFs:
for each “idx” in all frames - 1:
gap += square root of (bare-metal.frames[idx].delta- scaling[X] * VF[X].frames[idx].delta)^2
gap 就是最后的分数,理论上越小越好。
NOTES:判断质量的标准是图形是否足够接近物理机,如果不是用fps的阶梯而是fps本身的话,并不能充分反映”fps曲线形状“这个概念,请读者自行理解这里的区别。
这篇文章就到此结束,Farewell !